study
Embedding
Completion
“给一个任务描述、给少数几个例子、给需要解决的问题”这样三个步骤的组合,也是大语言模型里使用提示语的常见套路。一般我们称之为 Few-Shots Learning(少样本学习),也就是给一个或者少数几个例子,AI 就能够举一反三,回答我们的问题。
from openai import OpenAI
import os
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
COMPLETION_MODEL = "gpt-3.5-turbo-instruct" # "text-davinci-003"在2024年1月4号以后下线
def get_response(prompt, temperature = 1.0, stop=None):
completions = client.completions.create (
model=COMPLETION_MODEL,
prompt=prompt,
max_tokens=1024,
n=1,
stop=stop,
temperature=temperature,
)
message = completions.choices[0].text
return message
prompts = """判断一下用户的评论情感上是正面的还是负面的
评论:买��的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质
情感:正面
评论:随意降价,不予价保,服务态度差
情感:负面
"""
good_case = prompts + """
评论:外形外观:苹果审美一直很好,金色非常漂亮
拍照效果:14pro升级的4800万像素真的是没的说,太好了,
运行速度:苹果的反应速度好,用上三五年也不会卡顿的,之前的7P用到现在也不卡
其他特色:14pro的磨砂金真的太好看了,不太高调,也不至于没有特点,非常耐看,很好的
情感:
"""
print(get_response(good_case))
ChatCompletion
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
history = """User : 你是谁?
Assistant : 我是一个人工智能语言模型,可以回答各种问题,包括做菜的问题。
User : 请问鱼香肉丝怎么做?
Assistant : 鱼香肉丝的做法:
1. 猪里脊肉切丝,加入盐、淀粉、料酒搅拌均匀,腌制10分钟
2. 胡萝卜、青椒、木耳切丝备用
3. 热锅凉油,放入蒜末、姜末煸炒出香味,加入肉丝翻炒至变色
4. 加入胡萝卜、青椒、木耳翻炒,加入酱油、糖、醋、盐、味精、水淀粉搅拌均匀,倒入锅中翻炒均匀即可。
提示:鱼香肉丝的关键是调料的配比,酱油、糖、醋、盐、味精的比例要适合自己的口味。
User : 那蚝油牛肉呢?
Assistant : 蚝油牛肉的做法:
1. 将牛肉切成薄片,加入盐、淀粉、料酒腌制10分钟
2. 葱姜切末,蒜切片,青红椒切丝备用
3. 热锅凉油,放入葱姜末、蒜片煸炒出香味,加入牛肉翻炒至变色
4. 加入蚝油、酱油、糖、水淀粉调味,加入青红椒翻炒均匀即可。
提示:蚝油牛肉的关键是牛肉要切薄,翻炒时火候要快,保证牛肉口感鲜嫩。调味时,蚝油和酱油的比例也要适合自己的口味。
"""
def summarize(text, max_tokens=200):
response = openai.Completion.create(
model=COMPLETIONS_MODEL,
prompt=text + "\n\n请总结一下上面User和Assistant聊了些什么:\n",
max_tokens=max_tokens,
)
return response["choices"][0]["text"]
summarized = summarize(history)
print(summarized)
prompt = summarized + "\n\n请你根据已经聊了的内容,继续对话:"
conversation = Conversation(prompt, 5)
question = "那宫保鸡丁呢?"
answer = conversation.ask(question)
print("User : %s" % question)
print("Assistant : %s\n" % answer)
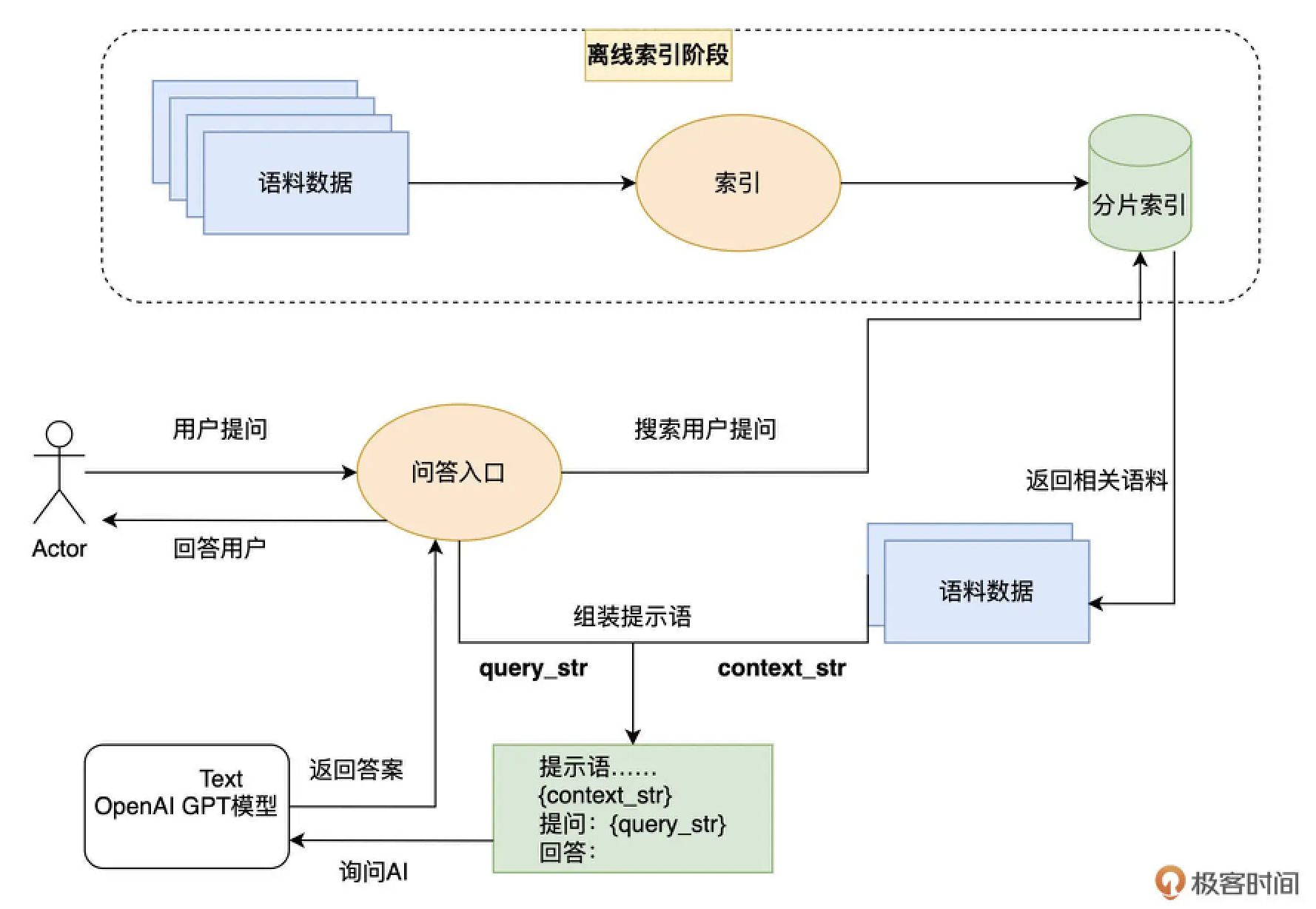
llama_index扩展
llama-index 其实给出了一种使用大语言模型的设计模式,被称之为“第二大脑”模式。通过先将外部的资料库索引,然后每次提问的时候,先从资料库里通过搜索找到有相关性的材料,然后再通过 AI 的语义理解能力让 AI 基于搜索到的结果来回答问题。
Gradio
通过Gradio封装现成的机器人